آموزش رایگان ماشین لرنینگ جلسه 8

یادگیری بدون نظارت
در جلسه قبل، یادگیری با نظارت رو بررسی کردیم که در اونا مدلها با استفاده از دادههای برچسبدار آموزش داده میشدند. اما در بسیاری از موارد ممکن است دادههای برچسبدار نداشته باشیم و نیاز داشته باشیم الگوهای مخفی رو از مجموعه دادهی موجود پیدا کنیم. برای حل چنین مسائلی در ماشین لرنینگ، به تکنیکهای یادگیری بدون نظارت نیاز داریم. پس چی شد؟ در یادگیری بانظارت، داده ها برچسب دارند و در یادگیری بدون نظارت، داده ها برچسب ندارند.
مثال: فرض کنید یک دیتاست شامل تصاویر مختلف از انواع گربهها و سگها داریم که البته توی این دیتاست برچسبی روی این عکسا نذاشتیم که کدوم گربه س و کدوم سگه. این دیتاست رو به الگوریتم یادگیری بدون نظارت دادیم. الگوریتم هیچگاه بر روی این مجموعه داده آموزش ندیده است، به این معنی که هیچ ایدهای از ویژگیهای مجموعه داده ندارد. وظیفهی الگوریتم یادگیری بدون نظارت اینه که بهصورت خودکار ویژگیهای تصاویر را شناسایی کند. الگوریتم یادگیری بدون نظارت این کار را با خوشهبندی دیتاست تصاویر به گروههایی براساس شباهتهای بین تصاویر انجام میدهد. یعنی الگوی نهان رو کشف می کنه و می فهمه که شکل های شبیه گربه رو در یه خوشه و شکل های شبیه سگ رو در یک خوشه دیگه بزاره بدون اینکه تحت نظارت ما از قبل بهش گفته باشیم اینا سگ و گربه است.
یادگیری بدون نظارت چیه؟
همونطور که از اسمش پیداست، یادگیری بدون نظارت یک تکنیک ماشین لرنینگ است که در آن مدلها با نظارت و برچسب گذاری ما آموزش داده نمیشن. در عوض، مدلها بهصورت خودکار الگوها و بینشهای مخفی را از دادههای ارائهشده پیدا میکنند. این روش رو میشه به یادگیری در مغز انسان وقتی میخواد چیزای جدید یاد بگیره مقایسه کرد. مثلا اگه 20 تا گوی به رنگ های سفید، سیاه و قرمز به ما بدن، مغز ما ویژگی رنگی رو درک می کنه و براحتی میتونه این گوی ها رو در سه خوشه بزاره.
یادگیری بدون نظارت نمیتونه بهصورت مستقیم برای مسائل رگرسیون یا طبقهبندی اعمال بشه، زیرا برخلاف یادگیری نظارتشده، ما دادههای ورودی داریم ولی دادههای خروجی مرتبط با اونا رو نداریم.
هدف یادگیری بدون نظارت اینه که ساختار زیرین دیتاست ها رو پیدا کنه، دادهها رو براساس شباهتها گروهبندی کنه و اون دیتاست رو بهصورت فشرده نشان بده.
چرا از یادگیری بدون نظارت استفاده کنیم؟
در زیر چند دلیل اصلی که اهمیت یادگیری بدون نظارت رو توضیح میدن آورده شده است:
- یافتن بینشهای مفید از دادهها: یادگیری بدون نظارت به یافتن الگوهای پنهان و بینشهای مفید از دادهها کمک میکند.
- شباهت به یادگیری انسانی: یادگیری بدون نظارت بسیار شبیه به یادگیری انسان از طریق تجربیات خود است، که آن را به هوش مصنوعی واقعی نزدیکتر میکند.
- کار با دادههای بدون برچسب و بدون دستهبندی: یادگیری بدون نظارت بر روی دادههای بدون برچسب و بدون دستهبندی کار میکند که این امر آن را به یک تکنیک مهمتر تبدیل میکند.
- کاربرد در دنیای واقعی: در دنیای واقعی همیشه دادههای ورودی با خروجیهای متناظر نداریم، بنابراین برای حل چنین مواردی به یادگیری بدون نظارت نیاز داریم.
نحوه کار یادگیری بدون نظارت
نحوه کار یادگیری بدون نظارت رو میتونیم با نمودار زیر توضیح بدیم:
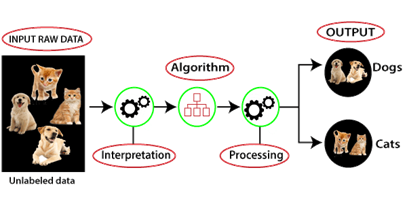
در اینجا، ما یک داده ورودی بدون برچسب داریم، یعنی داده ها دسته بندی نشدن (داده ما عکس هایی از سگ و گربه هست که عکسا کنار هم گذاشته شده و دسته بندی نداره) و خروجیهای متناظر نیز داده نشدهاند (یعنی برچسبی روی این دیتاها نزدیم که مشخص کنیم کدوم گربه هست و کدون سگ). فقط یک سری عکس داریم. حالا این داده ورودی بدون برچسب به مدل ماشین لرنینگ وارد میشه تا اونو آموزش بده. ابتدا، داده خام را تفسیر میکند (Interpretation) تا الگوهای مخفی رو از داده پیدا کنه و سپس الگوریتمهای مناسب (مانند خوشهبندیK-means، درخت تصمیمگیری و غیره – که همه این الگوریتم ها رو قراره بعدا یاد بگیریم) رو اعمال میکنه. پس از اعمال الگوریتم مناسب، الگوریتم داده ها رو بر اساس شباهتها و تفاوتهای بین اشیاء به گروهها تقسیم میکند. در اینجا به دو گروه تقسیم شده که هدف این شیوه از یادگیری ماشین همین بود دیگه. با تحلیلی که انجام داد، دیتاها رو تو خوشه های مختلف گذاشت.
انواع الگوریتمهای یادگیری بدون نظارت
الگوریتمهای یادگیری بدون نظارت رو معمولا میتوان به دو نوع مسئله تقسیم کرد:
- خوشهبندی (Clustering): خوشهبندی روشی برای گروهبندی اشیاء به خوشهها است به گونهای که اشیایی که بیشترین شباهت را دارند در یک گروه قرار گیرند و کمترین یا هیچ شباهتی با اشیاء گروه دیگر نداشته باشند. درواقع کلاسترینگ کارش اینه که اشیایی که بهم شبیه هستند رو کنار هم بذاره و اونایی که شباهت کمتری دارند به یه خوشه دیگه بفرسته. مثال های بالا از نوع کلاسترینگ بودند.
- همخوانی (Association): یک روش یادگیری بدون نظارت است که برای یافتن روابط بین متغیرها در پایگاه دادههای بزرگ استفاده میشه. درواقع این روش مجموعه آیتم هایی که توی یه دیتاست با هم اتفاق می افته رو تعیین می کنه. اَسوسیِیشن، استراتژی بازاریابی رو مؤثرتر میکنه. به عنوان مثال، افرادی که آیتم X (مثل نان) رو خریداری میکنند، معمولاً تمایل به خرید آیتم Y (کره/مربا) نیز دارند. پس این روش سعی میکنه رابطه بین متغیرهایی که درون دیتاست هست رو کشف کنه. یک مثال رایج از این نوع روش ماشین لرنینگ، تحلیل سبد خرید مشتریان (Market Basket Analysis) است (که به موقع اینارو باز میکنیم)
الگوریتمهای یادگیری بدون نظارت
در زیر لیستی از برخی الگوریتمهای محبوب یادگیری بدون نظارت آورده شده است:
- خوشهبندی K-means
- K نزدیکترین همسایهها یا KNN (K-Nearest Neighbors)
- خوشهبندی سلسلهمراتبی یا Hierarchal clustering
- تشخیص ناهنجاری یا Anomaly detection
- شبکههای عصبی یا Neural Networks
- تحلیل مؤلفههای اصلی یا (Principle Component Analysis –PCA)
- تحلیل مؤلفههای مستقل (Independent Component Analysis)


بسیار عالی لذت بردیم از این اموزش جذاب👏🙌
سپاس از همراهی. خوشحالم براتون مفید بوده